Data Machina
Data Machina 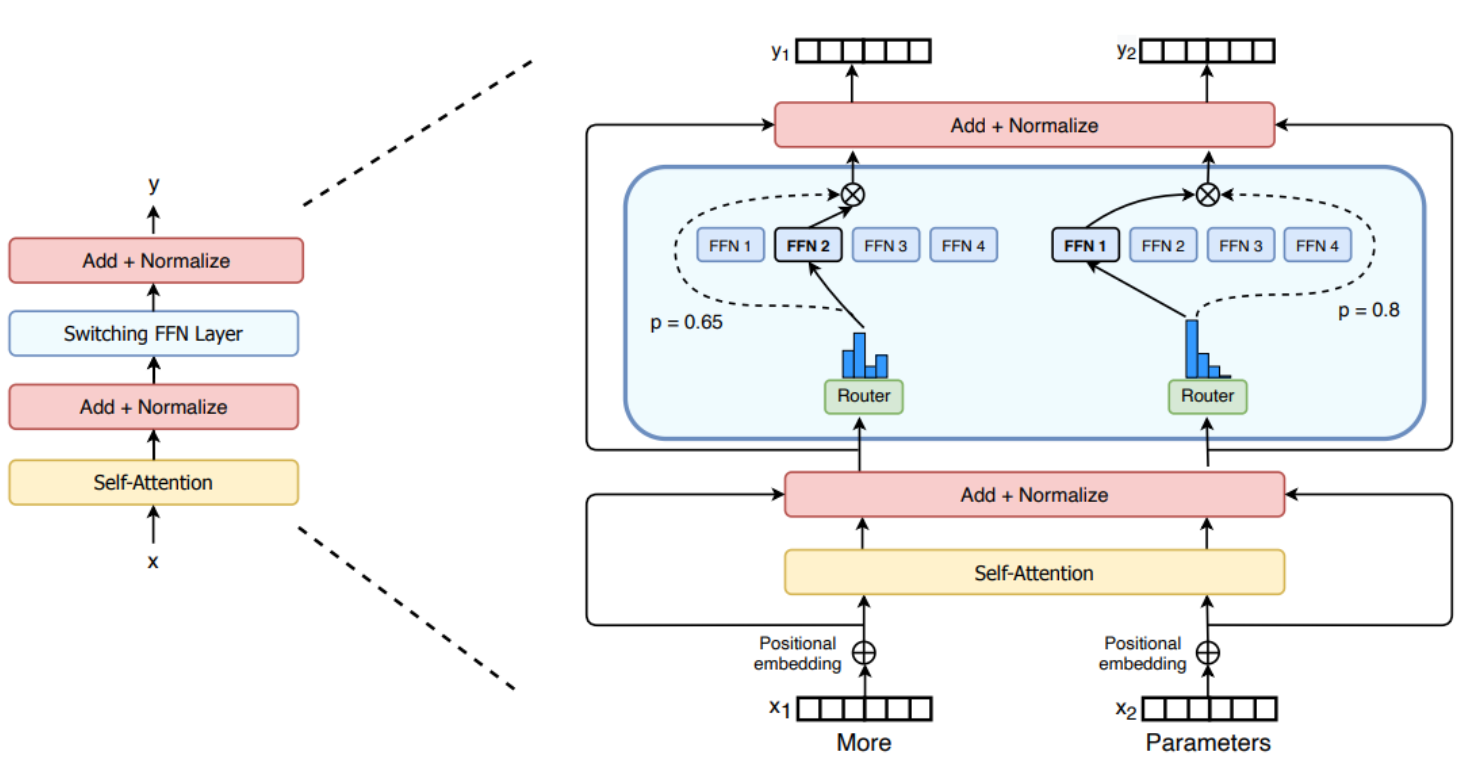
New Mixture-of-Experts (MoE) Models. I’ve read somewhere that Jeff Bezos once said that: “consensus & compromise between experts is not good for seeking truth.” Probably he is right. Well, it seems Mixture-of-Experts models are all the rage in the AI community these days. Let’s see why.
Dense transformer models are hugely demanding in terms of computational resources and model pipeline execution. MoE models provide faster pre-training, faster inference, and require less VRAM/compute resources. All the new MoEs models that are popping up recently, seem to outperform GPT-3.5 and Llama 2 models too.
How do Mixture-of-Experts models work? A group of leading AI researchers, just posted this excellent blogpost on MoEs. The researchers take a look at the building blocks of MoEs, how they’re trained, and the tradeoffs to consider when serving them for inference. Blogpost: Mixture of Experts Explained
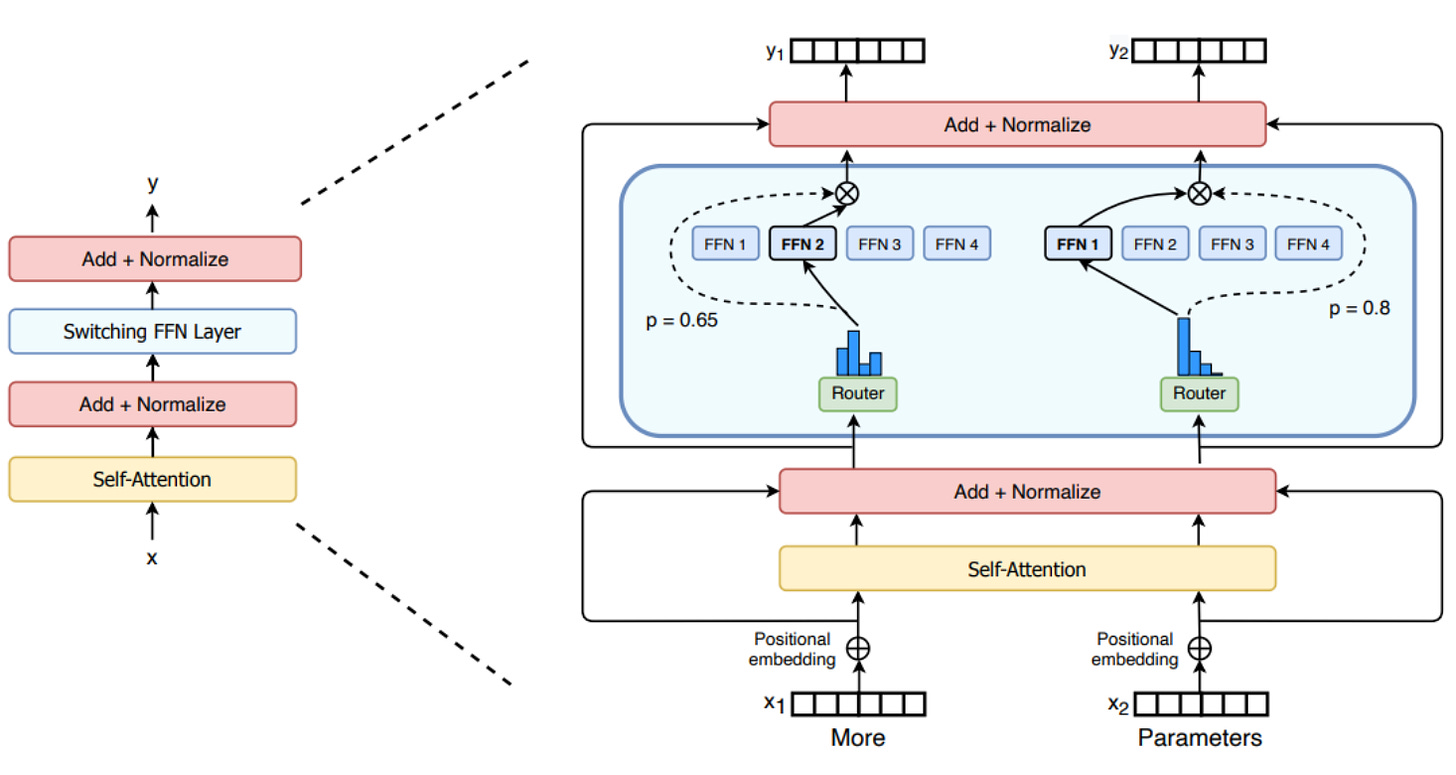
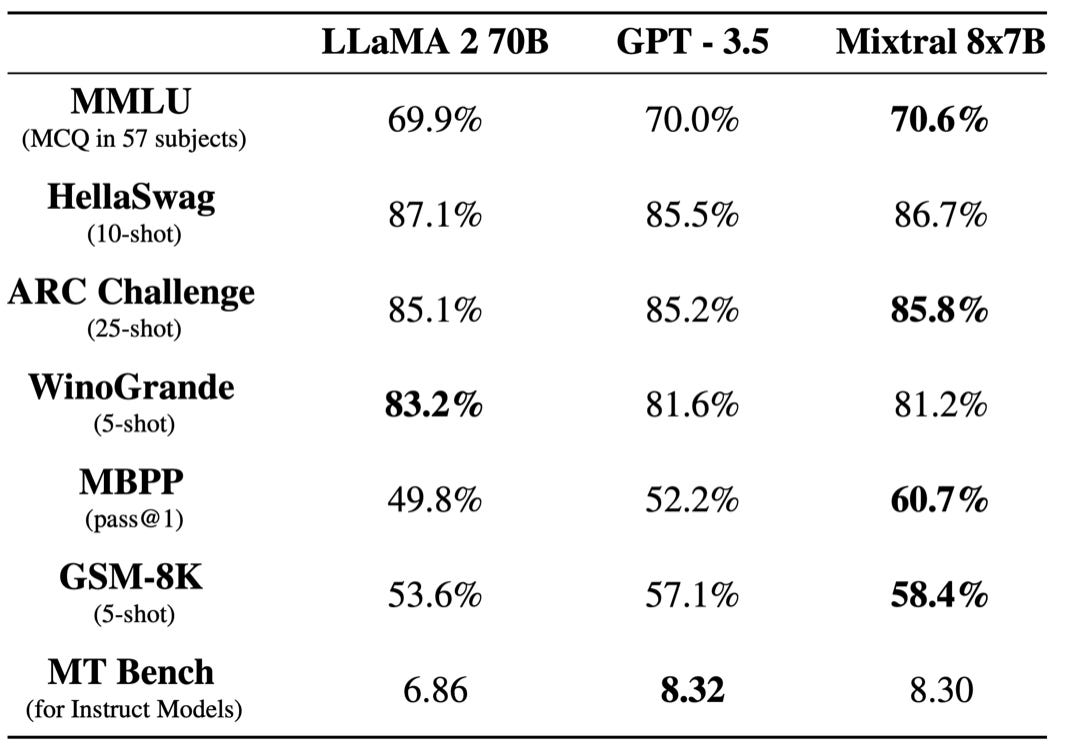
Mixtral-8x7B: A new SMoE model. Mistral AI just announced this high-quality, sparse mixture-of-experts (SMoE) model with open weights. Licensed under Apache 2.0. Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference. It’s the strongest open-weight model with a permissive license and the best model overall regarding cost/performance trade-offs. Blogpost: Mixtral of experts, A high quality Sparse Mixture-of-Experts.
Mixtral8-7B: Overview and fine-tuning. A great video explainer in which Greg reviews the architecture of Mixtral8-7B, and explains where it stands relative to other models, and how it differs from a classic transformer architecture. The video also includes a section on how to run inference using Mixtral and how to instruct-tune the model using Mosaic Instruct V3!
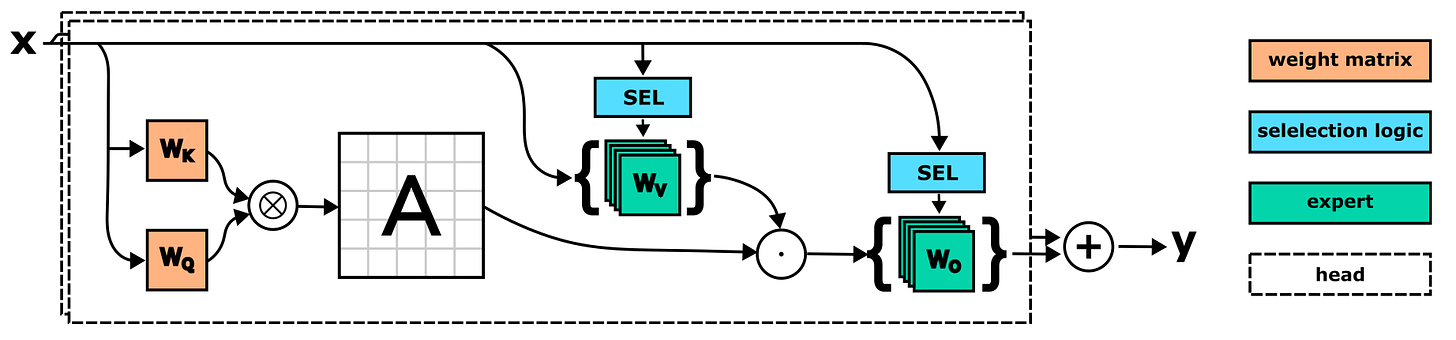
SwitchHead: A new MoE Attention model. Just a few days ago, a diverse group of AI researchers -including Schmidhuber- just released SwitchHead. The model uses Mixture-of-Experts (MoE) layers for the value and output projections and requires 4 to 8 times fewer attention matrices than standard Transformers. This novel attention model can also be combined with MoE MLP layers, resulting in an efficient fully-MoE “SwitchAll” Transformer model. Paper and source code: SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention.
CausalLM / Qwen with 8 MoEs. The awesome team at CausalLM have come up with a new model trained -note merged- on 8 completely different expert models based on Qwen-7B / CausalLM. Six of which are specific domain models including: a Toolformer/Agent expert model, a multilingual translation expert model, a mathematics expert model, a visual expert model, a coding and computer expert model, and an uncensored knowledge model — along with Qwen-Chat and Qwen-Base models. Checkout model description and repo: CausalLM / Qwen 8x7B MoE - This is not Mixtral / Mistral 7B
Running Mixtral1 8x7B on the new Apple MLX. A couple of days ago, Apple just published a repo on how to run Mixtral1 8x7B MoE model on the brand new MLX framework. This example also supports the instruction fine-tuned Mixtral model. Repo: Mixtral1 8x7B on Apple MLX example.
Have a nice week.
10 Link-o-Troned
Google Research - Advancements in ML for ML
MSR Phi-2 2.7B: The Surprising Power of Small LMs
DeepMind Imagen 2 - Our Most Advanced Img-to-Txt Model
The New StripedHyena 7B Models: Beyond Transformers
A Hacker's Guide to Open Source LLMs (12/2023)
A Systems Programmer's Perspectives on Generative AI
MS promptbase - A Repo on All Things Prompt Engineering
[free book] Deep Learning: Foundations and Concepts, Nov 2023
the ML Pythonista
Samsung AI: Diffusion Models + Flow XGBoost for Tabular Data
Google AI Gemini API - Getting Started Notebook
Spin up a Swarm of 10,000 Internet Agents, Let Them Work for You
Deep & Other Learning Bits
High Dimensional, Tabular DL Aided with a Knowledge Graph
[free course] RL with Human Feedback (RLHF)
[free NeuroIPS2023 tutorial] On World Models, Agents & LLMs
AI/ DL ResearchDocs
Introducing Automated Continual Learning (ACL)
Dense X Retrieval: What Retrieval Granularity Should We Use?
CogAgent: A SOTA Visual Language Model for GUI Agents
data v-i-s-i-o-n-s
1,374 Days: My Life with Long COVID
[interactive] Cost of Living: Why Things are Expensive?
How Many Hobbits? 3,000 Years of Middle Earth Population History
MLOps Untangled
How to Setup VS Code for AI/ML & MLOps in Python
BricksLLM: AI Gateway for Putting LLM In Production
The Big Dictionary of MLOps & LLMOps
AI startups -> radar
Relevance - Build & Deploy Your Own AI Agents with No Code
Delphina - A Copilot for Data Science & ML
Typeface - A Platform for Personalised Enterprise GenAI
ML Datasets & Stuff
The AI Art Dataset - 200k Txt-to-Img Prompts
UTD19: Largest, Public Multi-city Traffic Dataset Available
Toxic DPO - A Highly Toxic, Harmful Dataset for DPO & AI Unalignment
Postscript, etc
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
 Healthcare Informatics Magazine
Healthcare Informatics Magazine  The New York Times » Technology
The New York Times » Technology  Ciente Blog
Ciente Blog  Law Web
Law Web  TechRepublic
TechRepublic