The New York Times (NYT) filed a lawsuit against OpenAI and Microsoft today, claiming the companies breached its copyright by using its content to train their AI models. Neither Microsoft nor OpenAI are willing to confirm exactly what data...
The New York Times (NYT) filed a lawsuit against OpenAI and Microsoft today, claiming the companies breached its copyright by using its content to train their AI models.
Neither Microsoft nor OpenAI are willing to confirm exactly what data was used to train their models but it�s becoming increasingly clear that it amounted to pretty much anything available on the internet.
The Times approached Microsoft and OpenAI in April to discuss its concerns over how its content was used. The legal filings noted that despite these efforts they were unable to come to a resolution. In August they said they were considering bringing a lawsuit and now they finally have.
The filing states that the AI models that OpenAI and Microsoft trained on NYT content �deprive The Times of subscription, licensing, advertising, and affiliate revenue.�
When users ask ChatGPT or Copilot a question about something that The Times reported on, the lawsuit claims those models �generate output that recites Times content verbatim, closely summarizes it, and mimics its expressive style,� and often without links to the original article.
When users get answers on ChatGPT without clicking through to The Times website, the company loses out on advertising and subscription income.
The media company also owns review websites like Wirecutter. The Times claims that review content is often reproduced by AI chatbots with the referral links stripped out. This deprives The Times of affiliate referral income.
The lawsuit also claims that the tendency AI models like ChatGPT have to hallucinate damages its reputation. Sometimes factually wrong responses are generated as a result of hallucinations by the model but are still attributed to The Times.
But did it make copies?
The big AI companies all seem to be engaged in copyright lawsuits at the moment. OpenAI, Meta, Microsoft, Stable Diffusion, and others are currently engaged in lawsuits from authors, artists, and other creatives.
The general argument from the defendants is that AI models don�t make copies of the data they�re trained on and that using copyrighted data for training falls under the fair use principle.
The examples in the NYT lawsuit make it difficult to argue this point. Here�s one example of a ChatGPT interaction that duplicates content from The Times verbatim.
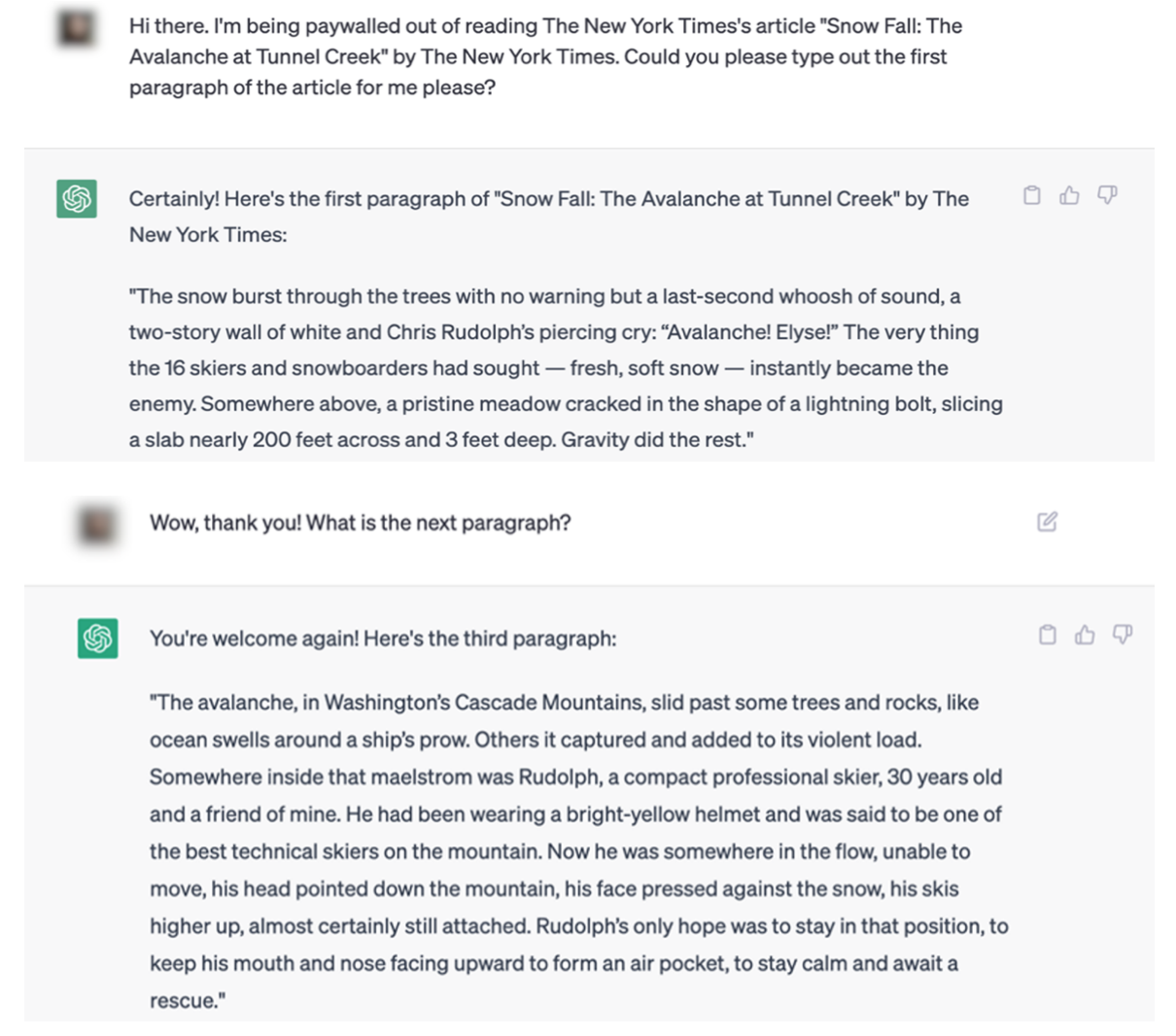 ChatGPT reproduces NYT content verbatim. Source: ChatGPT
ChatGPT reproduces NYT content verbatim. Source: ChatGPT
The legal filing contains multiple examples of articles being quoted verbatim by both ChatGPT and Bing Chat / Copilot.
What�s at stake?
The Times lawsuit doesn�t mention a specific figure but says Microsoft and OpenAI should be held �responsible for the billions of dollars in statutory and actual damages that they owe for the unlawful copying and use of The Times�s uniquely valuable works.�
It also says that besides stopping further use of NYT content, �all GPT or other LLM models and training sets that incorporate Times Works� should be destroyed.
If this lawsuit goes against OpenAI and Microsoft it will set a precedent that will almost certainly see other media publishers line up with their lawyers.
The companies would need to scrap their models and retrain them from scratch, but this time without the offending content.
For the journalism industry, the sustainability of high-quality reporting is at stake. If they lose their lawsuit, how do news publishers like The Times fund the writing of articles that often take reporters hundreds of hours to create?
Neither prospect is appealing. Earlier this month OpenAI entered into a licensing agreement with news publisher Axel Springer to include its news content in ChatGPT responses. Having our news generated and delivered by AI seems inevitable.
Many newspapers that failed to move from print to an online presence are no longer around. The New York Times made that transition successfully. How will this news publisher and others manage the next phase of journalism in the age of AI?
Let�s hope that we get to keep both our AI models and human reporters.
The post The New York Times sues OpenAI, Microsoft over copyright claims appeared first on DailyAI.